
Machine Learning with AWS
Posted by Pranjal on February 22, 2017
AWS has come up with Artificial Intelligence related services. One of the prominent one under that is Machine learning. Using this you can quickly setup a model that you can use to get predictions.
Machine learning can broadly be classified into
- - Supervised learning
Regression
Classification - - Others
Clustering - - Unsupervised learning
Reinforcement learning
Recommender systems etc.
Out of the above AML (Amazon Machine learning) currently only supports Regression and Classification. Within regression and classification AML currently only uses Linear Regression (squared loss function + SGD) and Logistic Regression (logistic loss function + Stochastic Gradient Descent (SGD)) algorithms. These algorithms are being used since these provide simplicity and scalability for a wide variety of applications.
However, what AWS has done with ML is something that AWS is already very well known for. It has made the interface and the process really straight forward. All you need to focus on data collection (which arguably is most important part of any ML process) and rest of it AWS takes care of automatically. So as long as you can provide a valid dataset AWS will:
- Carry out mean normalization
- Data splitting into training and test dataset. In fact if you wish to split dataset in Train | Cross validation | Test set even that is possible.
- Evaluate models and use the best ones
- You can easily visualize the dataset before you start the process (And we all know how important it is to visualize and validate your data before you spend lots of time creating model)
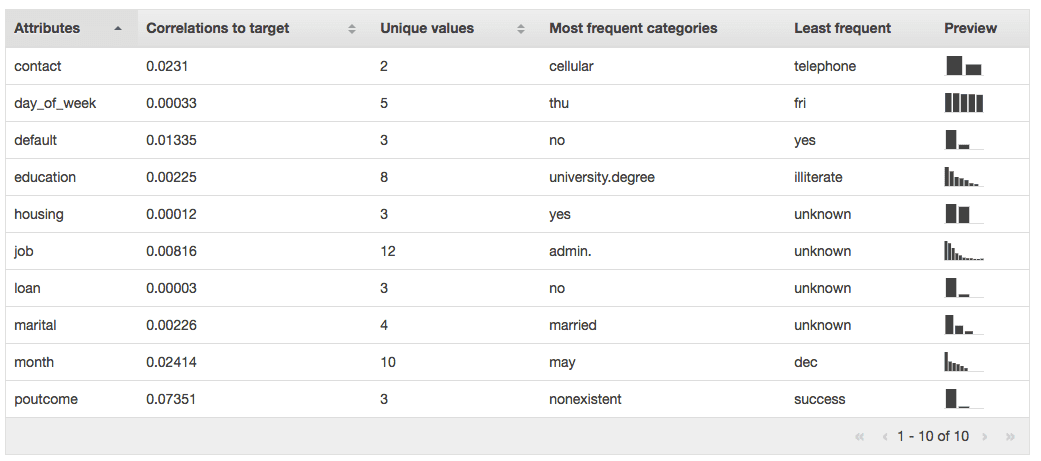
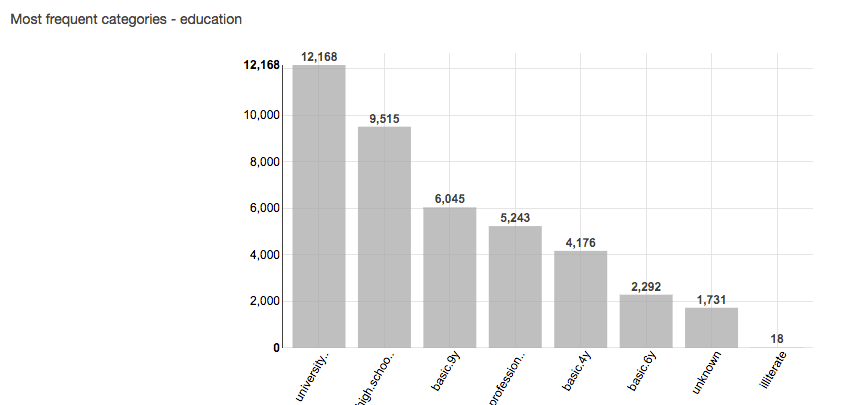
So, what all this does is, allows you to focus completely on the problem you are trying to solve and leave the low level details to AWS.
So AWS runs the process in the typical wizard flow and lets you:
- provided the dataset, selected the most appropriate data types and target
- Based on your data set and field types, AWS suggests a useful default, however you get a chance to modify default settings.
- This is where you can tweak with regularization settings
- You can select whether you want to run evaluations on your dataset and how you want to split the dataset for the same.
Based on these steps you can easily generate the model. The time taken to generate the model will directly be proportional to dataset size.
Once you have generated the Model, you can run evaluation to see how good the model is.
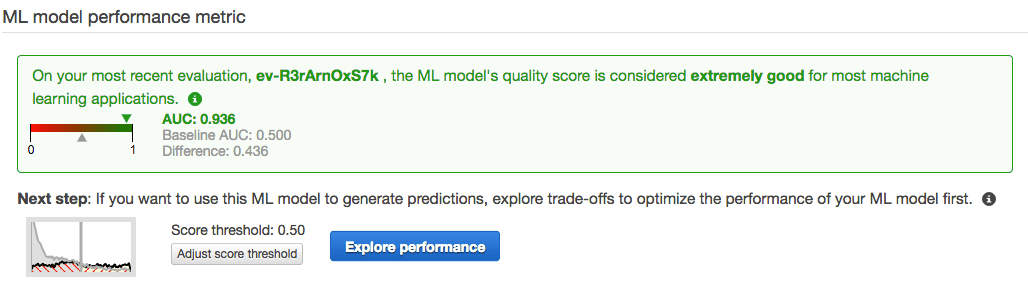
It provides a really easy to use interface to select the score threshold, and gives you all the information to decide on what the best threshold should be.
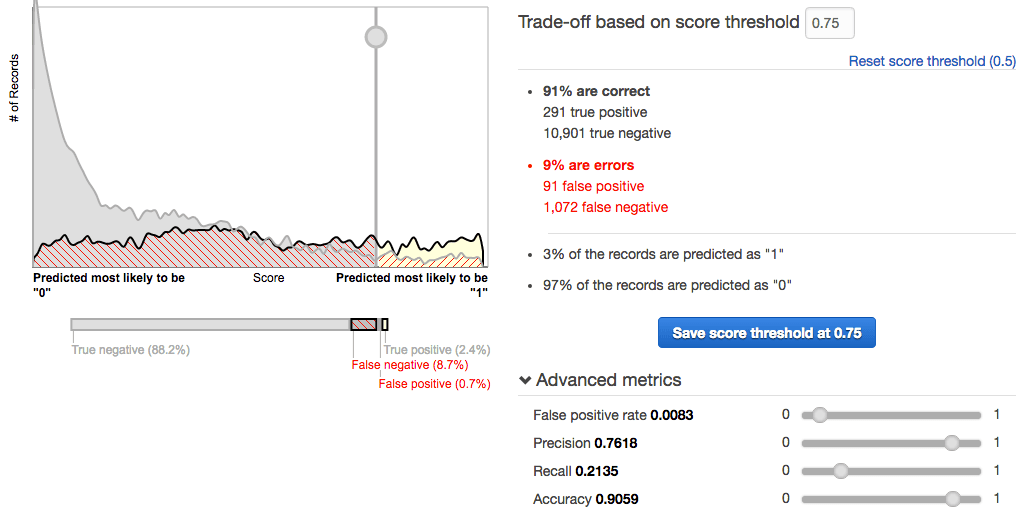
Once you have the model setup and you can use it in 2 different ways to use the model:
- You can generate batch predictions, where in you can upload CSV of dataset for which the prediction needs to be made
- You can setup an endpoint for real time predictions which you can use in your applications.
So, I think AWS has simplified the process so much that even someone with limited background in ML can use the system and get started with the process which is a huge plus and is truly a huge step in the direction of using ML as a service. Though there is a lot more that needs to be done, specially something to update the existing model easily with new observations since that will be very common with online model where there is continuous stream of data and user's behavior keeps changing with time.
 Business:
Business:  Call us on:
Call us on: H 92, Ground Floor. Sector 63, Noida, U.P
H 92, Ground Floor. Sector 63, Noida, U.P